고정 헤더 영역
상세 컨텐츠
본문
✔️ 3.7 데이터 사이언티스트가 던져야 하는 질문

[데이터, ML을 거론하기 전에...]
Q1. 쿠폰 지급 목적이 뭔가요?
- 홍보/성장? 규모 키우기인지
- 수익률 증가? 손익을 개선하고 이익률을 키우는건지
- 왜 이 프로젝트를 진행하게 되었는지
- 누구 누구가 담당자로 참여하는지
- 프로젝트 의사결정자는 누구인지...
Q2. 예산?
- 예산은 어떻게 산정이 되었는지?
- 내가 산정해야 하는지?
- 예산 외에도 제약사항이 있는지?
- 다른 제약사항 없는지, 내가 생각하는 제약사항 있는지?
Q3. 이벤트 '성공' 여부의 척도는?
- 내가 아는 그 척도/정보가 다른 사람들과 동일한지, align이 맞춰져 있는지
*알고리즘이나 기술적인 면모보다도 이런 측면에서 어려움을 겪고 실패하는 경우가 더 많음
데이터와 기술로 학습을 할 수 없으니 중요한 것임을 더욱 인지하고 가야함
[DS;Data Scientist 프로젝트 성공 꿀팁, 실패를 피하기 위한]
a. 무슨 데이터가 있고 어떤 세련된 기법을 활용할 것인가를 묻기 전에,
어떤 결과/정보를 얻고 싶은지가 먼저
- 필요한 결론이나 분석이 뭔지 그려보고 이 결과를 내기 위해서 어떤 데이터가 필요한지
그 필요한 데이터가 이미 있는지, 없다면 어떤 프록시로 얻을 수 있는지...
- 어떤 데이터/모형/기법은 자연스럽게 정해짐
b. 코딩 전, 기대하는 최종 결과(가설)를 먼저 구상
- 어떤 결과가 나올지에 대해, 실제 결과를 보기 전 최대한 고민
- 나와 동료들이 업종, 고객 등에 대해 알고 있는 것들을 취합해서 어떤 결과가 나오는 것이 가장 상식적일지 고민한 후에 우리가 이러저러한 것을 기대한다고 미리 적어두고
- 코딩 이후에 결과와 어느 정도 일치하는지 불일치한다면 이유가 무엇일지 등을 회고해야...
- 어떤 식으로 의사결정에 도움이 될지 또한 실용적으로 고민
c. 어떤 형태로든 '인과관계분석'은 피해갈 수 없다!
- 인과와 상관관계,... 인과의 증명은 어렵지만 의미있고 도움이 되는 분석을 위해 '인과분석'을 피해갈 수는 없음
- 과학적으로 정확한 결과를 도출할 수 있는 경우 (e.g 쿠폰을 줬기 때문에 이 사람은 구매한거다! 라는 확신)
- 다만 정확한 결과가 아니더라도 데이터에 기반한 부정확한 결과/분석이라도 의사결정에 도움이 될 수 있음
- 인과관계 분석에 대한 이해를 가지고 어디까지 말이 되고/안되는지 내 결과의 오점은 알자.

✔️ 3.8 다양한 의사 결정 상황에서의 분석 및 실습
[앞으로의 수업 개요]
- 간단한 의사 결정 상황 제시
- 실증적인 결과 기반으로 실습
- 필요에 따라 이후 관련 이론 소개
[의사 결정 상황]
- 경영진: 배송비 무료 쿠폰이 무슨 효과가 있어? 해/말아?
- 유용한 결과: 쿠폰 지급 전/후의 각종 성과 지표에 대한 예측
- 필요한 모형: 다양한 성과지표에 대한 쿠폰의 효과 (인과관계!)
*쿠폰에 의해서 성과가 나왔다라는...
[알고 싶은, 하지만 절대 알 수 없는 것]
특정 유저를 대상으로
- 배송비 무료 쿠폰을 줬을 때의 행동
- 배송비 무료 쿠폰을 안 줬을 때의 행동
두 가지를 동시에 관찰할 수 없는 것이 인과관계 분석을 못 한다는 이유
[알고 싶은 건 아니지만,알 수 있는 것]
비슷한 유저 집단을 모아두고
- 배송비 무료 쿠폰을 줬을 때의 행동
- 배송비 무료 쿠폰을 안 줬을 때의 행동
Google Colab 실습 진행
pkg import, data loading, train/test data split 완료
과거 데이터에서 쿠폰을 받은 사람과 받지 않은 사람 구분하여 비교
- 테스트 데이터로 쿠폰을 받은/안 받은 사람 구분하는 index 생성
- 구매 여부를 판단하기 위해 checkout 확인 및 평균 구하기
- 쿠폰 여부에 의해서 구매율이 얼마나 다른지?

6.9% 정도 쿠폰 받은 사람들이 구매율이 높았음
쿠폰 때문에 7% 높은 구매율을 보였다 라고 말하고 싶다면
쿠폰을 받은/안 받은 사람들이 쿠폰 여부 제외하고는 유사한 집단이라는 것을 증명해야 함
이전 데이터에서 쿠폰 발급 여부를 정말 랜덤하게 했다면...
쿠폰을 받은 사람들이 더 많이 사나? 장바구니가 더 커지는지 확인하기 위해서는
- checkout 대신에 basket을 봄
- 쿠폰을 받은 사람과 안 받은 사람의 평균 장바구니
basket_with_coupon - bakset_no_coupon
100원 차이 정도 남; 유의미한 결과인지 모르겠음

전반적인 유저 성향, 유저 featured를 가지고 좀 더 smooth하게 모아보자
checkout_ct=ColumnTransformer
다른 모형을 비교하려면 cross-validation을 해야하지만
지금 실습의 목적은 하나의 모형을 가지고 어떻게 활용하는지를 보는 것 위주.
*실무에서는 아무 모형이나 fitting하는 것보다는 여러 개를 해서 성과 좋은 것을 선택

각 유저가 쿠폰을 받았을 때의 구매율 변화 - 의 평균: 약 7% (유사함)
#1 유저를 두 그룹으로 나눠서 두 그룹 간의 차이를 계산한 것
#2 모델을 활용해서 두 그룹으로 나눴지만, 나눠서 모든 유저에 대한 행동을 예측한 것
전체적인 유저에 대한 평균을 구하게 되는 것
basket도 동일하게, 사용하는 feature 동일하나
XGBRegressor 사용
p_checkout이 아닌 e_basket 사용
predict_prob 아닌 predict

(e_basket_wtih_coupon - e_bakset_no_coupon).mean()
0.00011203... 아주 작은 차이
즉 장바구니(=결제금액) 차이는 크게 없지만
구매율 자체가 바뀌니까 유저들에 대한 기대 매출은 달라질 수 있겠음
매출에 대한 기대는 장바구니(=결제금액) * 구매 전환율
차이는 2,144원 정도

쿠폰을 주지 않았을 때의 기대치 대비 쿠폰을 줬을 때의 기대치는 120% 증가...

차이가 2,100원인데 어떻게 120% 증가가 될 수 있는거지...?
쿠폰 안 받은 유저 A의 결제금액 1만원
쿠폰 받은 유저 B의 결제금액 1.2만원 이라고 해서 120%의 증가인건가..?????
✔️ 3.9 인과관계분석 (Casual inference)의 학풍
Rubin-Neyman causal model
- 통계 기반의 인과관계 분석법
- 관찰되지 못한 결과(potential outcome)이 핵심
*즉 인과관계라는 것을 알기 위해서는 treament, intervention을 했을 떄와 하지 않았을 때
우리 세상에서는 둘 중 하나밖에 못 보기 때문에 다른 하나때문에라도 관찰되지 못한 결과가 있음
*estimation, 통계학 journal 등
Judea Pearl causality *후디아 펄, 컴퓨터 사이언티스트
- 데이터/그래프 기반의 분석법
- 원인과 결과 간의 관계에 대한 철학적인 논쟁이 핵심
어떤 행동이 무언가의 이유가 된다는 것, cause가 된다는 것은 어떤 의미일까?
비교
- 실증적으로 결과적인 계산/결론은 똑같음 (어떤 숫자를 계산하느냐를 보면 똑같!)
- 접근법/사고의 차이
[인과관계란?: 관찰되지 못한 결과(potential outcome)의 관점에서]
키 크는 약의 효과 > 이 약은 정말 '성장'의 원인인가?
- 종빈이가 먹고 한 달만에 2cm 성장
- 종빈이가 먹지않고 한 달만에 1cm 성장
> 키 크는 약은 종빈이에게 1cm 성장을 유발 (인과)
현실적인 문제
종빈이는 약을 먹거나 먹지 않을 수 있지만, 둘 다 할 수는없다.
즉 인과관계 계싼에 필요한 두 고나측치 중 하나는 관측이 불가능함
부족하지만 직관적인 접근법
- 전/후관계(pre/post) > 인과관계?
e.g 약을 먹어서 감기가 나은 건지? 아니면 자연스레 나은건지?
정확히 알려면 두 개의 평행우주에서 약을 먹어보고/안 먹어보고를 봐야하므로...
- 최대한 종빈이와 비슷한 사람 찾기
종빈이를 두 번 관찰할 수 없으므로, 종빈이와 유사한 사람들을 모아서 그룹으로 비교
[Average Treatment Effect]
개인적인 효과(treatment effect)는 알 수 없지만
어느 집단에 대한 평균적인 효과는 측정 가능
Average Treatment Effect (ATE)

[인과관계 분석을 위한 중요한 가정]
#1 Selection bias
- 처방 여부(assignment)와 각 (potential) outcome 간의 상관관계가 없어야 함
#2 SUTVA: Stable Unit Treatment Value Assumption
- 한 참가자의 처방 여부가 다른 참가자에게 영향을 미치지 않음
- 처방의 종류가 동일

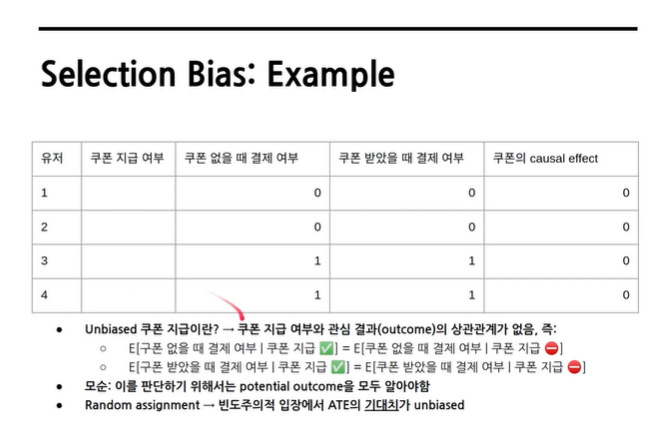
#1 Selection Bias: Example



실제 쿠폰 효과와 다른 결과가 나옴, 구매율을 낮춘다는 잘못된 결론을 내리게 됨.
쿠폰을 주던/안주던 결제를 할 사람들과 쿠폰을 주던/안주던 결제를 안 할 사람들에 대한
assignment가 잘못 구해져서 나온 잘못된 결과값
unbiased된 assignmnet는 어떤 것? Random assignment!
여러 번의 실험의 기댓값, 평균은 실제값에 수렴할 것이다
#2 SUTVA: Example
- 택시 앱에서 '무료승차권' 효과를 측정하기 위해 random assignment로
유저 50%에게 무료 승차권 지급 AB테스트
- 실험 결과, '무료승차권' 받은 유저의 승차율이
승차권 받지 못한 유저보다 훨씬 높음 (5배 높음)
- 실제 무료승차권의 순순한 '효과'는 측정치(5배)보다 낮을 가능성이 큼, 왜?
- 한 유저 집단의 급격한 승차율 증가가 자연스럽게 다른 유저 집단의 승차율에도 영향을 미침 : SUTVA 위반
즉 택시의 수는 한정되어 있는데 무료승차권을 가진 사람들이 많이 타기 시작하면, 없는 사람들이 못 탈 수도 있고
무료승차권을 가진 사람들의 수요가 늘어나서 택시비가 올랐을 수도 있고...

참고.
Casual Inference by Imbens and Rubin
Casality by Judeal...
✔️ 3.10 예산 제약 하에서의 이벤트 계획 및 의사 결정 실습
[의사 결정 상황]
경영진: 예산은 얼마나 필요한가? 5천만원 투자하면 구매율이 얼마나 오르나?
이벤트 비용/투자 예산에 의한 예측 구매율
어떤 데이터/모형이 필요할까?
- 과거 데이터만으로는 어려움
- 유저 수가 몇천에서 몇만이 되었다거나... >
(1) 현재 유저 데이터 current_users.csv
(2) 쿠폰 지급 전/후 각 유저의 구매율 예측 모형
(3) 쿠폰 지급에 따른 비용 예측 모형
- 고정 비용 제외: 배송비 무료 쿠폰의 비용은 실제 배송비
- 배송료: f(basket, region)
*장바구니 크기에 따라서 무료배송이 되는 경우, 지역 별로 배송비 다르고, 해외 배송은 장바구니의 크기나 종류에 따라 달라짐
- 구매금액(basket) 예측 모형
- 현재 유저 데이터의 미래 대표성에 대한 가정
*지금 갖고 있는 유저 데이터가 이후 배송비 무료 프로모션 운영 시에 유저 특성을 대변할 수 있는지


실습시간...!

checkout 확률에서 쿠폰 효과를 측정하기 위해
test data에서 쿠폰을 받았을 때, 안 받았을 때를 나눠서 Column 추가

predict 함수를 주면 우리가 원하는 결과가 basket이라는 column으로 적용됨

shipping_fee=shipping_fee.pipe.predict
basket 예측하고 > 그걸 shipping_fee에 적용해서 계산 가넝
연간 회원들은 shipping_fee가 양의 값일 수 있어도 실제로는 내지 않았음
실제 비용을 계산하려면 연간 회원의 shipping_fee는 뺴줘야 함
Actual shipping_fee를 계산해야하고 이를 위해서
subscriber 여부를 포함해야 함
actual_shipping_fee=lambda d: d.shipping_fee *(1-d.subscriber)
subscriber면 shipping_fee를 0처리 한다는 것
그럼 coupon_spend 계산할 수 있음
coupon _spend=lambda d:d.actual_shipping_fee*d.p_checkout_with_coupon,
쿠폰을 받은 유저가 결제를 할 때 shipping_fee가 결제되는 것
비용 대비 효과를 계산해보자.
effect_per_spend=lambda d:d.coupon_effect/d.coupon_spend
쿠폰의 효과/쿠폰의 비용

metrics로 저장함.
이 metric으로 여러가지 시뮬레이션을 운영할 수 있음
n,_=metrics_df.shpae 몇 명이나 있는지 데이터 모수가
쿠폰을 줬을 때 비용이 적게 드는 사람부터 쿠폰을 줘보자
metrics_df
. sort_values ('coupon_spend', ascending=True)
. rest_index()
. assign
비용이 어떻게 축적되는지 계산
cum_spend=lambda d: d.coupon_spend.cumsum()
est_increase=lambda d:
d.p_checkout_with_coupon.cumsum()/n 쿠폰을 받았을 때,안 받았을 떄에..
d.p_checkout_no_coupon.cumsum()/n 쿠폰을 받았을 때,안 받았을 떄에..
population에서 증가하는지 알고 싶음
전체 고객에 대한 구매율의 평균이 알고 싶으므로
아무한테도 쿠폰을 안 준다면을 전제했을 때 구매율이 성과지표의 기준
p_checkout_no_coupon.mean()
+ 한 사람씩 쿠폰을 줄 때 마다 구매율이 얼마나 올라가는지
한사람에게 쿠폰을 줬을 때 전체 유저 중 몇 프로에게 준 것인지?
1로만 채워진 column을 만들어서 cumsum/n으로 나누면, 몇 프로의 유저들에게 나눠줬는지 알게됨

sns.lineplot(
x=cum_spend
y=est_checkout
쿠폰 아예 없을 때의 전환율은 5.5% 정도
전체 유저에게 쿠폰을 다 주면 2.5억 정도, 12%의 구매 전환율

비용이 가장 적은 순으로 주자고 했던 기준을
효과가 가장 좋은 순으로 주자라고 바꿔 보자면

일반화하기 위해 계산했던 것들을 함수로 만들어주면
coupon_spend 기준 혹은 coupon_effect 기준, effect_per_spend 등...
여러 개의 데이터를 테이블로 취합할 수 있음
세 개의 데이터프레임을 하나의 데이터프레임으로 합치는 것

세 개의 데이터프레임을 하나로 plotting하면
세 개의 그래프가 나오고, 5천만원 선이면 결제율 몇프로 정도 나오는지 확인이 가넝



✔️ 3.11 ML을 이용한 인과관계 분석의 한계와 주의점
[예측 모형을 이용한 ATE 계산]
전제에는 어떤 일이 벌어지고 있는 걸까?
feature들이 유사한 집단이 있고 여기가 쿠폰을 받았을 때 결제율이 n% 였다...
쿠폰을 받지 않았지만 다른 면에서 비슷한 유저 집단을 찾아서 비교



머신러닝을 통해서 그룹의 상황과 결론을 교환해 보는 것
Assuming ignorability (response surface modeling)

우리가 가진 feature가 한정되어 있으므로
관찰하지 못한 미지의 변수가 매우 많음
쿠폰을 받는지 여부와는 상관관계가 있으나 결과엔 없거나
결과와는 상관관계가 있으나 쿠폰 여부와는 없거나 등
두 가지 중 하나만 성립할 경우 ignorability 만족
Ignorability 위반의 예
우유 마심(assignment) > 키가 큼 (outcome)
우유를 마셨기 때문에 키가 크다?
관측되지는 못했어도 어떤 이들에게는 우유를 더 좋아하고 잘 마시는 유전자가있을 수도?
그치만 그 유전자가 키와는 무관하다면 분석 결과에는 영향 없음



[추가 주의사항]
Treatment assignmnet 이후에 관측된 정보 (e.g 쿠폰을 받은 이후에 관측된 정보) 사용 불가
- 결제금액(쿠폰 적용 전) 배송료는 최종 결제여부와 상관관계 있음
- 이를 feature로 포함할 경우checkout에 대한 예측 성과 올라감
- 하지만 이는 배송비 무료 쿠폰 지급 이후 관찰한 항목이므로 이를 포함하면 coupon에 대한 인과관계 분석 불가능
사용 예측 모형이 암시하는 바에 대해 주의
- e.g 선형 모형을 사용할 경우 interaction의 부재가 시사하는 바?
- 대부분 최대한 유연하면서 예측 성과가 우수한 모형 (XGBoost)을 사용함녀 크게 문제되지 않음


✔️ 3.12 수익 극대화 이론 및 실습
[의사 결정 상황]
상장도 했고... 성장/구매율보다는 이익에 초점을 맞춰보자.
쿠폰을 얼마나 지급하느냐(쿠폰 지급 비중)에 따라 이익이 얼마나 증가하냐
필요한 데이터/모형
- 예산 제약 계산에 사용된 데이터/모형/가정
+ 쿠폰 지급에 따른 이익 = 수익-비용 계산
-

Colab 실습~.~
Checkout estimation
Basket estimation
Shipping fee estimation
Metric computation
- coupon_effect
- Actual shipping fee estimation
- Spend, effect per spen estimation
- Revenue estimation
기본 수익부터 계산하기,
즉 쿠폰을 안 줬을 때의 계산부터. (=base revenue)
base_revenue=d.p_checkout_no_coupon*d.basket
coupon_revenue=d.p_checkout_with_coupon*d.basket
marginal_revenue 두 개의 차액, d.coupon_Revenue-d.base_Revenue
여기까지는 수익이고
이익은 비용을 빼야함
marginal_profit=d.marginal_revenue-d.coupon_spend
수익과 이익의 증가분을 축적해서 보는 것
여러가지 sorting 기법에 따른 차이 확인하기

극대화를 위해서 유저의 50% 정도까지 쿠폰을 주는 것
쿠폰을 나눠주는 기준을 매출/수익의 극대화로 한다면?

쿠폰을 나눠주는 기준을 이익(profit)의 극대화로 한다면?
8,000만원까지 marginal_profit이 올라감

구매율을 본다면?
- 구매율은 marginal_revenue이 marginal_profit보다 좋음
즉 구매자수를 늘리는 것이 목적인지 이익을 늘리는 것이 목적인지에 따라 달라짐!
절대적으로 쓸 수 있는 예산의 제약이 있다면 그것까지 감안해야함


[중요한 질문]
배송료 무료 쿠폰의 비용 = 배송료?
- 유저에게 부과하는 배송료와 기업이 부담하는 배송료 다를 수 있음!
- 이외의 비용은 없는지?
예상 이익의 불확실성
- 유저 기반 변화 *이 모형을 만들 때의 유저가 이벤트 진행 시 유저를 대변한다는 것 (population)
- Basket 예측 모형 오차
- Network effect (SUTVA 위반)
✔️ 4.1 행복한 데이터 사이언티스트로 살기
1. 호기심과 늘 배우려는 자세
- 내 일에 대해 방어적이지 않도록 노력
- 절대적 권위자 X 새로 배울 것 투성 O
2. 정밀/정확/명료함 (precision and clarity)
- 대충 얼버무리고 넘어가면 나중에 고생
- 정확하지 않은 것은 모른다고 인정
- 정확하지 않아도 괜찮은 것은 의도적/공개적으로 정확하지 않다고 분명하게 함
- 가장 중요한 것은 투명성/명료함 (clarity)
3. 유쾌하고 합리적인 의심
- 내가 한건데,. 유명한... 가 .. 에 속지 말 것
- 새로운 문제/해법을 당면했을 때 한 발 물러서서 최대한 의심의 눈초리로 꼼꼼히 볼 것
- 직관적이지 않고 놀라운 일에 현혹되지 말고, 직관이 생길 때까지 의심, 깊이있게 탐구!
하지만...
- 이 모든 과정에서 유쾌하고 즐겁게 임할 것
- 만사에 불평하고 의심하는 사람으로 비춰지기 쉬움
4. 목적에 대한 초점과 자신감
- 호기심, 정확도, 의심을 좇다가 궁극적 목적을 잃기 쉬움
- 때로는 불만족스러운 상황에서의 도전 필요
- '무모한' 도전이 아닌 목적이 분명한 의도적 도전
- 불확실성에 대해 인정하기
5. 윤리의식
- 생각하지 못한 사이에 의도치 않게 많은 영향력을 갖기 쉬움
- 늘 본인의 '선'이 무엇인지 미리 고민
돈을 벌기 위해 나는 어떤 일까지 할 것인가? 얼마까지?
커리어를 위해 무엇까지 포기할 수 있는/없는가?
닥쳤을 때는 늘 쫓기고 생각을 정리할시간이 없어 실수하기 쉬움..
e.g 우버에서 1마일 당 비용 분석 > 미국 전역으로 공유
- 본인의 가치관을 일관적으로 지키기 위한 구체적인 노력이 필요





댓글 영역